Mastering Data Quality in Data Science with PySpark Insights
Written on
Understanding Data Quality and PySpark
Imagine it’s a warm afternoon, and you decide to take a stroll. As you walk, you see people enjoying delicious ice cream cones—flavors like mint chocolate, Cookies & Cream, and French vanilla adorned with whipped cream, hot fudge, and crunchy toppings. This sight makes you ponder: how did this delightful treat ignite your cravings?
To indulge in your ice cream sundae, each component must be meticulously prepared and packaged—from the ice cream itself to the toppings. To get to that stage, you first need high-quality milk. Reflecting on the process, it all begins with milking cows, who are nourished with grass.
Dairy Quality Insights through "Pie-Spark"
How does this ice cream analogy relate to data quality? Let me clarify. Motivated by the need to enhance Dairy Quality (DQ) or Data Quality, I needed to utilize "Pie-Spark," also known as PySpark, to effectively transform real-world data. Poor quality milk would ultimately compromise the ice cream’s value. Similarly, to identify data quality issues, we must ensure that clean and reliable data is generated before any transformations occur in the data pipeline. This often requires data profiling through exploration to identify and address potential quality issues.
Here are some challenges you might encounter as a data professional:
- An attribute may not be parsed correctly due to changes in its name or format in the source data.
- An attribute might be missing from the source due to a bug or alteration in the application.
- An unexpected situation may lead to an incorrect number of events being produced.
- A mandatory attribute could be absent due to issues in event generation or information processing.
- Unique values may be duplicated.
Q: How did Adidas Runtastic tackle these challenges?
They needed a solution to address these data quality concerns. Their initial approach involved running a batch job every 24 hours to convert the incoming raw binary data into text. This process also included parsing the data and organizing it into flat, relational tables, enabling downstream analytical services to access it through standard JDBC connections via Hive queries. Data quality checks were performed in batches after preprocessing to avoid disrupting operations.
Q: What was their solution?
They employed the "unittest" Python library and wrote a job for each entity type, leveraging Spark’s efficient parallel computation.
For those interested, here’s a useful article to read while on the go in your Adidas gear:
How to Use PySpark for Big Data Sanity Testing and Data Quality Evaluation
In Runtastic’s Data Engineering team, we depend heavily on Hadoop and its services for data ingestion and preprocessing...
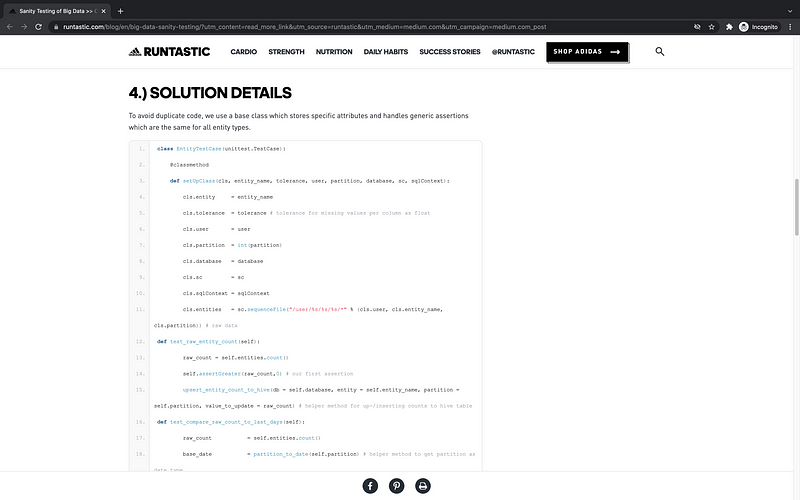
To see the code implementation from Runtastic, check out the screenshot below:
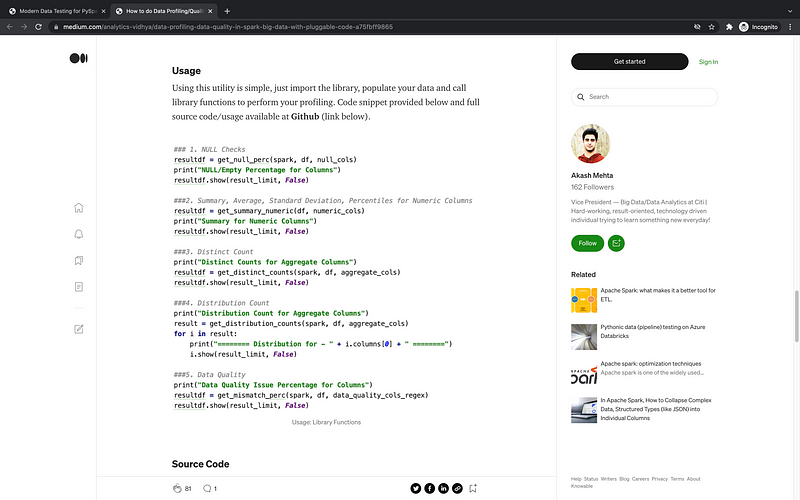
Additionally, I’ve included a screenshot from Akash Mehta’s article featuring a code snippet on data profiling in five simple steps:
- NULL Checks
- Summary, Average, Standard Deviation, Percentiles for Numeric Columns
- Distinct Count
- Distribution Count
For further learning, here are three additional YouTube videos that delve into Data Quality and PySpark:
Building Data Quality Pipelines with Apache Spark and Delta Lake
Explore the importance of data quality pipelines in maintaining clean datasets using Apache Spark and Delta Lake.
Data Quality on Apache Spark
Learn effective strategies for ensuring data quality when working with Apache Spark.
Additional Resources for Data Quality and PySpark
Expand your knowledge further with these insightful resources.
Thank you for reading! I hope you found this article valuable. Follow me on Medium for more insights.