Unlocking the Potential of Meta’s Code-Llama Models
Written on
Chapter 1: An Overview of Code-Llama
Meta's Code-Llama represents a new family of large language models (LLMs) built on the Llama2 architecture, specifically tailored for coding applications. This model comes with several enhancements and distinctions compared to earlier coding LLMs.

Introducing The Family Members
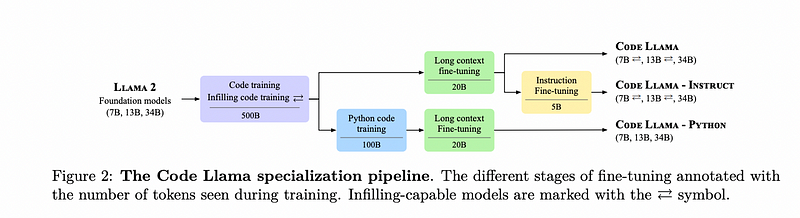
Code Llama Specifications
The Code-Llama models are available in three different sizes: 7B, 13B, and 34B. The smaller models (7B and 13B) are trained with infilling objectives to optimize their performance in integrated development environments (IDEs). All versions utilize Llama-2 weights and are trained on an extensive dataset comprising 500 billion tokens of code, including long context data.
Python-Specific Enhancements
The models specializing in Python also come in sizes of 7B, 13B, and 34B. They focus on understanding the variances between a single programming language model and more general coding models. The Python version builds on the Code Llama architecture, trained specifically on 100 billion tokens, and is adept at managing longer contexts without infilling.
Instruction-Focused Variants
The Code Llama — Instruct model is designed to improve user interaction by closely following human instructions. This model is trained on 5 billion tokens composed of human-generated directives.
Training Methodology Compared to Previous Models
Prior coding models like AlphaCode, StarCoder, and InCoder were built from the ground up using solely coding data. In contrast, Code-Llama adopts an approach akin to Codex by beginning with a foundational model trained on a mix of general-purpose text and code, allowing it to surpass models trained exclusively on coding data.
Dataset Construction
For training Code-Llama, a dataset containing 500 billion tokens was meticulously curated from publicly available code, with 8% of the data sourced from natural language discussions related to coding. The data underwent tokenization using Byte Pair Encoding (BPE), consistent with Llama and Llama2 models.
Infilling Techniques
While autoregressive training (next-token prediction) is beneficial for code completion, it falls short for filling gaps in text. Therefore, an infilling objective is incorporated, enabling models to generate code at the cursor position within IDEs and produce docstrings. The training documents are segmented into three parts—prefix, suffix, and middle—formatted in two distinct ways: PSM (prefix, suffix, middle) and SPM (suffix, prefix, middle).
Addressing Long Context Challenges
Handling longer sequences than those encountered during training poses a significant challenge for LLMs. Code-Llama incorporates a dedicated finetuning phase aimed at long context training using sequences of up to 16,384 tokens, following methodologies established by Chen et al. (2023).
Instruction-Tuning Datasets
To create the instruction-tuned models, Code Llama — Instruct, three datasets were utilized. The first is a proprietary dataset from Meta, designed for training Llama2 with human feedback. The second dataset consists of 14,000 question-test-solution triplets generated through automation, reducing reliance on human annotators.

Subsection 1.1.1: Generating Unit Tests
For each question in the dataset, unit tests are generated by prompting Code Llama 7B.

Training Insights
The final dataset used for Code Llama — Instruct is a rehearsal dataset, serving to prevent regression in both code generation and natural language instructions. This dataset includes 6% of the code dataset and 2% of the natural language dataset.
Key Training Parameters
The training parameters for Code Llama include: - Optimizer: AdamW (Beta1=0.9, Beta2=0.95) - Scheduler: Cosine Scheduler (1000 warm-up steps) - Batch Size: 4 million tokens presented as sequences of 4,096 tokens - Learning Rate: Varied based on model size, with 3e-4 for 13B models, 1e-5 for 34B, and 1e-4 for Python finetuning.
Chapter 2: Evaluating Model Performance
The first video, "Introducing CODE LLAMA - An LLM for Coding By Meta," explores the innovations behind the Code-Llama models and their practical applications in coding.
The second video, "Code Llama Unlocked: The New Code Generation Model," provides insights into how this advanced model enhances coding efficiency and effectiveness.
Performance Insights
The results of the training and evaluation indicate that specialization significantly enhances performance. The transition from Llama2 to Code-Llama and subsequently to Code-Llama Python shows marked improvements in code generation capabilities. Additionally, a variant known as Unnatural Code Llama, fine-tuned on the Unnatural Instructions dataset, demonstrated superior performance among the Llama family, though it still trails behind GPT-4.
Multi-Language Evaluation
Code-Llama consistently outperforms Llama2 across various programming languages, including Python, Java, C++, C#, TypeScript, and PHP. However, the Python-specific model shows slightly reduced performance compared to the general Code-Llama.
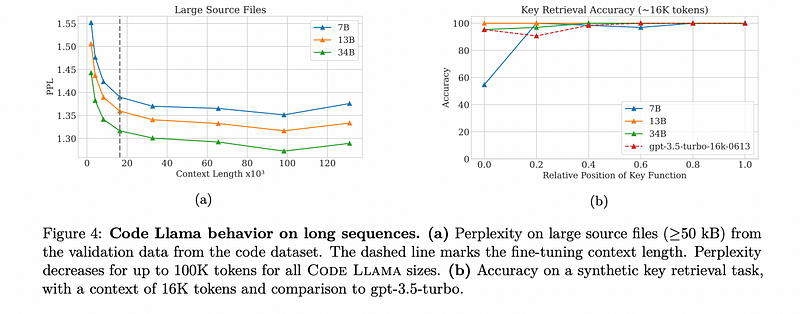
Long Context Evaluations
To assess long context performance, the Meta team conducted experiments focusing on perplexity during extrapolation, revealing that perplexity declines after 16,000 tokens, indicating effective extrapolation capabilities. However, beyond 100,000 tokens, perplexity begins to rise.
GitHub Repository for Code Llama
We hope this article has been informative. If you found it useful, please express your support through claps, comments, and follows. Connect with us on LinkedIn: Aziz Belaweid and Alaeddine Abdessalem.

Stay updated with the latest AI developments by connecting with us on LinkedIn. Together, let’s shape the future of artificial intelligence!
