Transformers and Attention: A Deep Dive into Modern AI
Written on
Understanding the Transformer Framework
The influential paper titled “Attention is All You Need” authored by Vaswani and colleagues introduces the transformer architecture. This particular neural network structure leverages the attention mechanism and serves as the foundation for contemporary large language models (LLMs) like ChatGPT, GPT-4, and BERT.
Below are key points to clarify the transformer architecture and its attention mechanism.
The Transformer Framework
Transformers handle sequences of tokens, which can be (sub-)words in a sentence. The transformer framework has two main components:
- The encoder, responsible for processing the input token sequence.
- The decoder, which generates new tokens based on the input and previously produced outputs.
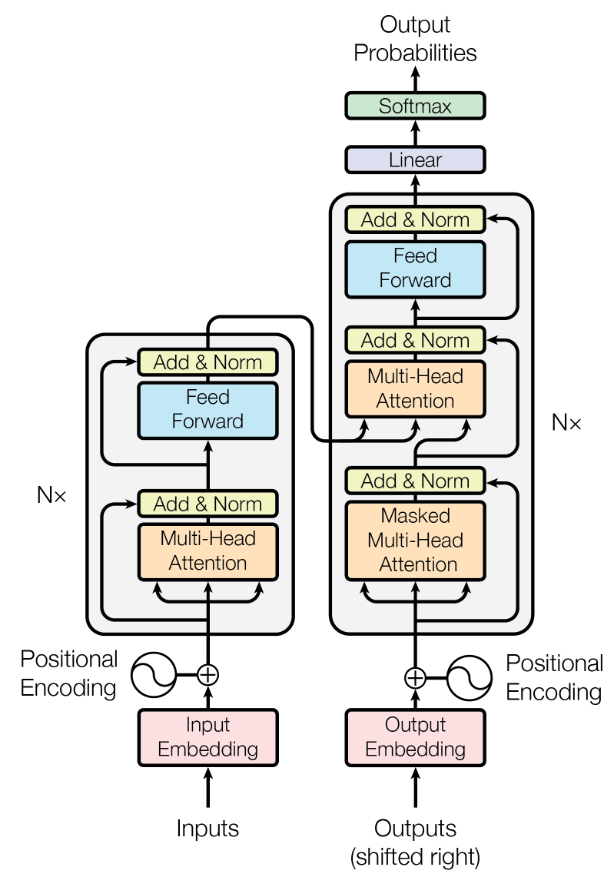
The comprehensive layout of this architecture is illustrated below, with the encoder on the left and the decoder on the right.
Encoder
The encoder (illustrated on the left) processes the input token sequence. Initially, each token is transformed into a d-dimensional vector, often through methods like word2vec. Each token is then analyzed individually and compared with others within the input.
Following the token embeddings, a positional encoding is incorporated, which signifies the absolute and relative positions of tokens in the sequence. This step is crucial for various tasks, especially in natural language processing, because later parts of the encoder do not differentiate token positions. This lack of distinction may overlook vital information. For instance, in the sentence “The cat watches the dog run fast,” swapping the positions of “cat” and “dog” would change the subject and object, thus altering the sentence's meaning. The authors in the paper input the word positions into sine and cosine functions and add the results to the input vectors.
After positional encoding, a self-attention block is applied. During self-attention, tokens within the input sequence are compared to each other to calculate attention weights. A high attention weight for a pair suggests a syntactic or semantic relationship, indicating which tokens the model should focus on. In the sentence “The cat watches the dog run fast,” the tokens “run” and “fast” might receive high attention due to their semantic connection, while “the” and “fast” would likely have low attention weights. Detailed discussions on attention will follow in subsequent sections.
Ultimately, a standard feed-forward neural network follows the attention block, producing encoded tokens sequentially. This encoder block, which includes both the attention mechanism and the feed-forward network, can be replicated multiple times, with the final encoded tokens being fed into the decoder.
It is essential to note that both the outputs from the attention and feed-forward blocks are added back to their original inputs and normalized using residual connections. These connections assist in back-propagating gradient updates, which might otherwise be diminished.
Decoder
The decoder (located on the right side of the architecture) closely resembles the encoder but focuses on the output sequence. It takes both the encoded input tokens and the tokens produced thus far as inputs. Utilizing this information, the decoder generates new tokens, whether translating the input into another language or summarizing the text.
As with the encoder, the tokens in the output sequence are embedded into d-dimensional vectors and supplemented with positional encodings that correspond to their position in the output sequence. They are then processed via self-attention, comparing the tokens in the output sequence against one another.
Unlike the encoder, the decoder incorporates a cross-attention block that compares the encoded input tokens using cross-attention. This cross-attention mechanism is central to the decoder, aiding in the generation of the next output token by considering both the entire input and the previously produced outputs.
Similar to the encoder, the decoder contains a fully-connected feed-forward neural network following the attention blocks. The decoder can also be stacked multiple times. Eventually, a linear layer followed by a softmax activation outputs probabilities for all potential tokens, selecting the one with the highest probability as the next token. This process continues until a special end-of-sequence (EOS) token is chosen, allowing for the generation of output sequences of varying lengths, independent of the input sequence length.
The Attention Mechanism
At the heart of the transformer architecture lies the attention mechanism — hence the title “Attention is All You Need.” In a transformer, this mechanism enables the model to assign varying attention weights/scores to different tokens in a sequence. This allows the model to prioritize relevant information, disregard the irrelevant, and effectively capture long-range dependencies in data.
The attention mechanism involves three components: query Q, key K, and value V. Each token in a sequence serves as a distinct input for Q, K, or V. The mechanism assesses the relationship between queries Q and keys K to evaluate their significance and compatibility, calculating attention weights. It then selects the corresponding values V associated with high attention weights, akin to selecting values from a database based on matching keys.
Self-Attention & Cross-Attention
Self-attention and cross-attention differ primarily in the tokens assigned to inputs Q, K, and V. In self-attention, identical tokens are utilized for all three inputs — meaning each token serves as Q, K, and V. Conversely, in cross-attention, the same tokens are assigned to K and V, but different tokens are employed for Q.
Self-attention is applied to the input sequence within the encoder and to the output sequence in the decoder. The cross-attention module in the decoder utilizes the encoded input tokens as K and V while employing the produced output tokens as Q.
In both scenarios, attention weights between tokens in Q and K are computed using scaled dot-product attention. While alternative attention methods exist, such as learned attention weights, scaled dot-product attention is quicker and more space-efficient. In this method, attention weights are calculated without additional parameters, as depicted in the illustration below: Tokens in Q and K are multiplied, scaled, and passed through a softmax function to derive attention weights. These weights are then multiplied with the tokens in V to select values with high corresponding weights.
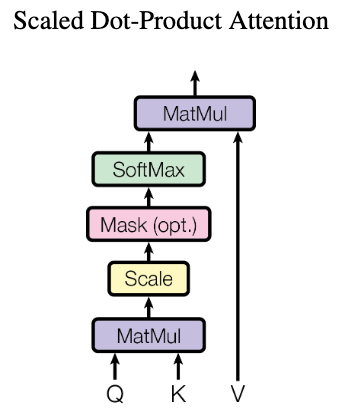
Example: Calculating Attention Weights
Consider the tokens “cat” and “dog,” where “cat” serves as query Q and “dog” as both key K and value V. The attention calculation proceeds as follows:
- The embedded Q and K tokens are multiplied via the dot product. For instance, if “cat” is represented as the vector (0.6, 0.3, 0.8) and “dog” as (0.5, 0.1, 0.9) — where we have d=3 dimensional embedding vectors — the dot product yields 0.6*0.5 + 0.3*0.1 + 0.8*0.9 = 1.05. Generally, embedding vectors are significantly longer (larger d) and can be derived using techniques like word2vec. The resulting product is larger for vectors that are more similar and closer in the embedding space.
- This product is scaled by dividing by ?d. In our example: 1.05 / ?3 = 0.606. If d is substantial, the dot product could become excessively large, making scaling essential for appropriate inputs to the softmax function.
- The scaled product is then input into a softmax function, generating the attention weights. The resulting attention weights for all token pairs range between 0 and 1, summing to 1. In our case, assume we have two additional token pairs with scaled products of 0.2 and -0.8 alongside our 0.606. Thus, softmax([0.606, 0.2, -0.8]) = [0.523, 0.348, 0.128], indicating the highest attention weights for “cat” and “dog” while the other pairs receive lower weights. Certain positions can also be masked (ignored) by setting them to negative infinity, resulting in softmax(-?)=0. This technique is employed in the decoder during training.
- The computed attention weights are then multiplied by the values V. In this example, “dog” is used as value, and its embedding vector (0.5, 0.1, 0.9) is multiplied by the attention weight 0.523, resulting in (0.262, 0.052, 0.471). Other token pairs with lower compatibility between Q and K may yield attention weights closer to zero, consequently reducing their values V to vectors near zero. The model will pay less attention to these values compared to those with higher attention scores.
Multi-Head Attention
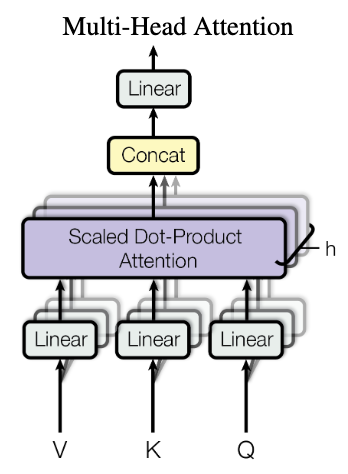
Multi-head attention applies the previously described attention mechanism multiple times (h times) simultaneously. Before sending input tokens of dimension d into these h attention blocks, they are projected into smaller embeddings of size d/h using small linear neural networks. Each of the h linear networks has distinct weights, leading to different projections. Consequently, each attention “head” can learn to focus on various aspects, such as the subject and object of a sentence. The outputs from the h heads are concatenated and processed through another linear neural network.
Multi-head attention is utilized in both self-attention and cross-attention blocks. Notably, increasing h enables the network to learn different types of attention, such as one head focusing on the subject, another on the object, and yet another on the verb of a sentence. The value of h is not directly tied to the sequence's length.
In summary, attention is a surprisingly straightforward yet powerful mechanism to highlight meaningful tokens while disregarding less significant ones. This mechanism allows transformers to capture context even in lengthy sequences, resulting in coherent outputs.
Useful Resources
- The original paper “Attention is All You Need” by Vaswani et al.
- Illustrated guide to transformers available on YouTube
- Slides titled “Transformers from Scratch” by Umar Jamil
The figures featured in this article are reproduced with permission from the paper ‘Attention is All You Need’ by Vaswani et al.